Cyrillkana
Syllabary derived from the letters of various cyrillic alphabets.
Preface
Context
This was a very odd endeavor I undertook over two days out of boredom. It resulted in a very strange syllabary in the form of a table, but without any explanation. Once I write up everything and put it in html form, I will update this page!
The Idea
The inspiration for this experiment came from a youtube video which explained the coincidental similarities between Japanese and Russian.
Later, in a state of complete boredom, I have revisited some pages related to both languages. Upon examining both of their writing systems, I have stumbled upon a set of characters from the Japanese and Russian scripts which share their corresponding sounds. These characters are:
| Sounds like English... | "a" | "e" | "i" | "o" | "u" | "ya" | "yo" | "yu" |
|---|---|---|---|---|---|---|---|---|
| Japanese hiragna | あ | え | い | お | う | や | よ | ゆ |
| Russian cyrillic | А | Э | И | О | У | Я | Ё | Ю |
This was the first step to a very silly exercise.
What I found interesting was that each of these vowels / morae were represented by one character in both scripts, which led to the following thought:
Is there a way to represent one language using the characters of the other’s while retaining a one-to-one correspondence between their characters?
The answer should have been no.
I was considering a cyrillic representation of Japanese and, while transliteration exists, there is no one-to-one character correspondence. Thus, to get around this, I created a cyrillic syllabary.
Design
The starting point for the exercise is a reduction of Japanese into hiragana (katakana works too, but I like hiragana), so each syllable can be represented by a cyrillic letter. Here is a full chart of hiragana characters:
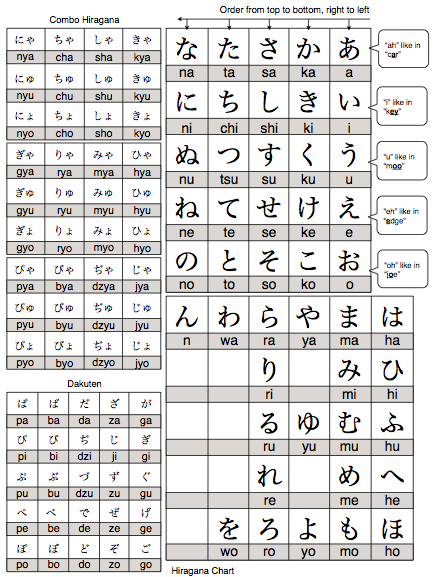
This table can be simplified further, as there are mainly voiced/unvoiced pairs which use the same characters but are differentiated by diacritics (dakuten and handakuten). The same distinction can be made in the cyrillic syllabary by adding a similar marker. As such, the new table of “totally unique” characters looks like this:
| a | i | u | e | o | |
|---|---|---|---|---|---|
| ∅ | あ | い | う | え | お |
| k | か | き | く | け | こ |
| s | さ | し | す | せ | そ |
| t | た | ち | つ | て | と |
| n | な | に | ぬ | ね | の |
| h | は | ひ | ふ | へ | ほ |
| m | ま | み | む | め | も |
| j | や | ゆ | よ | ||
| r | ら | り | る | れ | ろ |
| w | わ | を | |||
| -n | ん | ||||
The starting point are the aforementioned vowels and their iotated forms which we can insert here:
| a | i | u | e | o | |
|---|---|---|---|---|---|
| ∅ | а | и | у | э | о |
| k | か | き | く | け | こ |
| s | さ | し | す | せ | そ |
| t | た | ち | つ | て | と |
| n | な | に | ぬ | ね | の |
| h | は | ひ | ふ | へ | ほ |
| m | ま | み | む | め | も |
| j | я | ю | ё | ||
| r | ら | り | る | れ | ろ |
| w | わ | を | |||
| -n | ん | ||||
This is where the design challenge begins, as no other cyrillic letter (save for n) can solely represent these hiragana characters.
As such, the next step is to assign other letters to represent the Japanese morae. As the characters of hiragana neatly fit into consonant and vowel pairs, we can represent each character with a cyrillic letter of its respective consonant or vowel (so for the character "ま", we can represent it with the consonant "м" or the vowel "а").
However, there are 46 hiragana characters while the Russian alphabet contains 33 letters. We can fix this by including other cyrillic letters used in other languages, such as Ukrainian, Serbo-Croatian, and Early Cyrillic.
These letters were then categorized by phonetic similarities. As an example, the letters “н” and “њ” represent “n” and a palatized “n” (like “ñ” in Spanish) respectively, and were thus grouped together. This extended to voiced/unvoiced pairs, such as “к” and “г” (“k” and “g”), since we have simplified the hiragana table.
A table of the cyrillic letters which I have collected and organized are here:
| Similar to... | ||||||
|---|---|---|---|---|---|---|
| /k/ | к | г | ґ | ѯ | ||
| /s/ or /ɕ/ | с | ш | щ | ж | з | ѱ |
| /t/, /tɕ/, or /ts/ | т | ћ | ч | ц | ђ | џ |
| /n/ or /ɲ/ | н | њ | ||||
| /h/, /ç/, /ɸ/, /b/, or /p/ | х | ѳ | ф | г | б | п |
| /m/ | м | ꙟ | ||||
| /j/ | й | ј | ї | |||
| /ɾ/ or /l/ | р | л | љ | |||
| /w/, /β/, or /v/ | в | ў | ѵ | |||
| /a/ | а | ѧ | я | ꙗ | ||
| /i/ | и | і | ь | ы | ||
| /ɯ/ | у | ю | ꙋ | ъ | ы | |
| /e/ | э | е | є | ѣ | ѧ | ѥ |
| /o/ | о | ѡ | ѫ | ё |
And here are the (general) pronunciations of each hiragana character which I referenced:
| a | i | u | e | o | |
|---|---|---|---|---|---|
| ∅ | [a] | [i] | [ɯ] | [e] | [o] |
| k | [ka] | [ki] | [kɯ] | [ke] | [ko] |
| s | [sa] | [ɕi] | [sɯ] | [se] | [so] |
| t | [ta] | [tɕi] | [tsɯ] | [te] | [to] |
| n | [na] | [ɲi] | [nɯ] | [ne] | [no] |
| h | [ha] | [çi] | [ɸɯ] | [he] | [ho] |
| m | [ma] | [mi] | [mɯ] | [me] | [mo] |
| j | [ja] | [jɯ] | [jo] | ||
| r | [ɾa] | [ɾi] | [ɾɯ] | [ɾe] | [ɾo] |
| w | [wa] | [o] | |||
| -n | [n], [m], [ɲ], etc | ||||
I have made some initial assignments but was unsure about the placement of some characters.
| Consonant priority | |||||
|---|---|---|---|---|---|
| a | i | u | e | o | |
| ∅ | а | и | у | э | о |
| k | к | ґ | ѯ | ѯ | г |
| s | з | ш | с | щ | ж |
| t | ћ | ч | ц | т | ђ/џ |
| n | н | њ | н | н | н |
| h | х | х | ф | ѳ | ѳ |
| m | м | ꙟ | м/ꙟ | м | м |
| j | я | ю | ё | ||
| r | љ | љ | р | л | л |
| w | в | ѵ | |||
| -n | ь | ||||
| Vowel additions | |||||
|---|---|---|---|---|---|
| a | i | u | e | o | |
| ∅ | а | и | у | э | о |
| k | к | ґ | ѯ | е | г |
| s | з | ш | с | щ | ж |
| t | ћ | ч | ц | т | ђ/џ |
| n | а/н | њ | ъ/ы | н/ѣ/ѧ | н/ъ/ѫ |
| h | ѳ/а | х | ф | ѳ/э | ѳ/о |
| m | м | ꙟ | ꙋ | ѧ | ѫ |
| j | я | ю | ё | ||
| r | а/љ | љ/и/і | р | л/э | л/љ/ё |
| w | в | ѵ | |||
| -n | ь | ||||
This is the point where I have searched up the frequencies of hiragana and (Russian) cyrillic characters to assign the more frequent characters to each other, leading to this draft:
| a | i | u | e | o | |
|---|---|---|---|---|---|
| ∅ | а | и | у | э | о |
| k | к | ґ | ѯ | е | г |
| s | з | ш | с | щ | ж |
| t | д | ч | ц | т | ћ |
| n | ꙗ | њ | ы | ѣ | н |
| h | п | х | ф | б | ѳ |
| m | м | ꙟ | ꙋ | ѧ | ѫ |
| j | я | ю | ё | ||
| r | љ | і | р | л | ъ |
| w | в | ѵ | є | ѡ | |
| -n | ь | ||||
The lesser used "wi" and "we" were also included. As a final note, dakuten (voicing) is represented with an apostrophe after a character and handakuten ("h" to "p") is represented by the degree sign. As such "п", "п'", and "п°" represent "ha", "ba", and "pa" respectively).
Text Samples
I have tried out the cyrillkana conversions on a few words before applying it to Article 1 of the Universal Declaration of Human Rights.
Words
ひらがな → (hi ra ka’ na) → хљк'ꙗ
おちゃ → (o chi yu) → очю
とおまわり → (to o ma wa i) → ћомви
おかあさん → (o ka - sa n) → ок-зь
らーめん → (ra - me n) → љ-ѧь
せんせい → (se n se i) → щьщи
きんぎょ → (ki n ki’ yo) → ґьґ'ё
よこはま → (yo ki ha ma) → ёґꙗм
すうがく → (su u ka’ ku) → сук'ѯ
かるい → (ka ru i) → кри
かんい → (ka n i) → кьи ("Easy peasy" yeah right)
Cyrillkana
сб'т н њье'ь в, умл ꙗк'љ њ шт ш'юу т' аі, кц, жье'ь ћ еьі ћ њ цит ѳ'ёућ'у т' ар. њье'ь в, іщи ћ іёушь ћ ѡ зс'ељлтoі, дк'и њ ћ'уѳу н щишь ѡ ѫцт гућ'ушꙗелп'ꙗлꙗи.
Japanese
すべての人間は、生まれながらにして自由であり、かつ、尊厳と権利と について平等である。人間は、理性と良心とを授けられており、互いに同 胞の精神をもって行動しなければならない。
Closing
Upon seeing the final table and some sample conversions, my only thought was:
“Yes... this is something.”
I think this actually contributed a net negative to the world, as anyone who can read cyrillic will have a stroke reading cyrillkana, which the Russian and Ukrainian militaries are already weaponizing.
All jokes aside, there is room for improvement, as there are many more cyrillic letters which can be used for this system (as the ones I used are solely from Slavic languages). This can lead to a full syllabary not dependent on exterior marks to represent voicing. In addition, there's no system for represeting yōon in the same way Japanese does.
At the very least this inspires me to focus on a more serious and well designed orthographic project. That’s why my next one will be the creation of a hiragana alphabet :)
Otherwise, I may update this page soon by highlighting some stuff in the tables.
Further Samples
It was a pain creating the sample conversions and, while I wanted to include larger blocks of text, it would probably be easier to come up with a simple program to handle these conversions.
As such, for now, I leave the creation of further samples as an exercise to the reader.


